Poikkeamien tunnistaminen verkkosivuston analytiikkadatasta
Web-analytiikkaa on yleisesti tulkittu markkinoinnin ja liiketoiminnan tukitoimena joka näkyy asiakasymmärryksen lisäämisenä, konversio-optimointina, markkinointikampanjoiden tehokkuuden seurantana, sisällön optimointina, kustannusten hallintana tai yleisesti kilpailuedun ja kehittämisen mahdollistamisena.
Poikkeamien (anomalioiden) tunnistaminen web-analytiikan yhteydessä puolestaan on jäänyt yllättävän pienelle huomiolle web-analytiikkaan liittyvissä keskusteluissa ja artikkeleissa. Termi viittaa prosessiin, jossa pyritään tunnistamaan tai havaitsemaan odottamattomia ja epätavallisia tapahtumia tai ilmiöitä suuressa datamäärässä. Tällaisia poikkeamia voi olla web-analytiikan kontekstissa esimerkiksi seurannan ongelmat, jossa esimerkiksi uusin tuotannon versio sivustosta on rikkonut seurannan, dataputki ei toimi tai SQL-kysely ei ota huomioon tyhjiä arvoja (null). Myös muut epätyypilliset tapahtumat, jotka poikkeavat normaalista verkkovierailudatasta tai odotuksista voidaan havaita poikkeamia tarkastelemalla.
Hyvin monesti seurannan ongelmat havaitaan vasta kun poikkeamasta on kulunut jo hyvän aikaa, ja/tai se tajutaan vasta satunnaisen analyysin yhteydessä. Koko prosessi on automatisoitavissa ja poikkeamat ovat tunnistettavissa vain pienellä viiveellä!
Tämä kirjoitus ei ota kantaa tunnistettujen poikkeamien analysointiin tai niistä tehtävien johtopäätösten tekemiseen. Myös poikkeuksien tunnistamisessa, kuten kaikessa tekemisessä, on positiivisten ominaisuuksien lisäksi myös haittapuolet. Poikkeamien tunnistamisen kanssa tulee tilastoja havainnoida kriittisesti. Asioita joita tulee huomioida ovat muun muassa poikkeamat joita menetelmä ei tunnista, harvinaiset poikkeamat ja tämän tuottama bias, mittauksen epätarkkuus, satunnaisvaihtelut, ympäristön vaihtelut tai väärä analysointimenetelmä. Havainnoi aina poikkeamia kriittisesti ja pyri löytämään mahdollinen selitys poikkeamalle.
Miten voit lähteä tarkastelemaan oman verkkosivustosi dataa ja havainnoida sieltä löytyviä poikkeamia? Esitän kolme menetelmää: custom insights , standardipoikkeama ja koneoppimisen mallit . Custom insights on yksinkertaisin toteuttaa, mutta se on riippuvainen GA4-alustasta. Muut menetelmät vaativat datan varastointia muotoon jossa se on laskettavissa tai muutoin ohjelmallisesti käsiteltävissä.
Taso 1: GA4 custom insights
Tiesitkö, että GA4 käyttöliittymässä on olemassa ominaisuus jonka avulla voit tunnistaa yksinkertaisia poikkeamia GA4 datasta? Googlen sisäänrakennettu anomalioiden tunnistus hyödyntää niin aikasarja-analyysiä kuin pääkomponenttianalyysia (PCA). Aikasarja-analyysi tarvitsee kahden viikon harjoitusdatan, ja se ajetaan tämän jälkeen päivittäin. Pääkompontenttianalyysi etsii otannasta datan vaihtelun kannalta keskeisimmät datapisteet ja asettaa ne lineaariseksi joukoksi, huomattavasti joukosta eroavat datapisteet tulkitaan poikkeamiksi. Pääkomponenttianalyysi ajetaan GA4-järjestelmässä automaattisesti kerran viikossa. Kokonaisuutta ajatellen, custom insights on helpoin tapa tunnistaa poikkeamia sivustolta ja on hyvin yksinkertaista kytkeä päälle!
Toimi näin:
Avaa GA4 käyttöliittymä https://analytics.google.com/analytics/web/#/ ja navigoi vasemman laidan valikosta “reports”-osioon. Reports snapshot sivulta etsi “Insights” widget ja valitse “View all insights”.
Insights sivulta valitse oikean yläreunan sinisellä taustalla piirretty painike “Create”.
Ikkunasta valittavissa on kahden tyyppisiä mittareita
- Ennalta määritellyt mittarit
- Itse luotavat mittarit
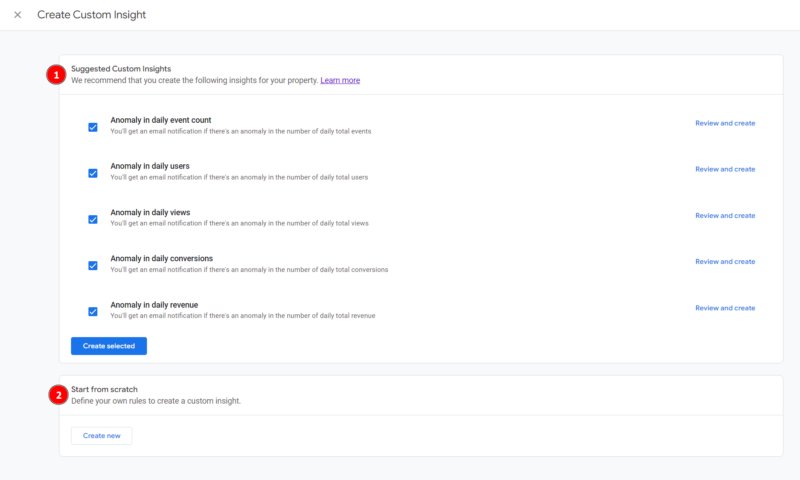
Riippuen sivuston tyypistä ja liikenteen määrästä tulee miettiä mitkä anomalia-mittarit kannattaa kytkeä päälle. Mikäli sivustolla on paljon kausivaihtelua tai kampanjoinnista aiheutunutta vaihtelua, saamme huomattavan määrän virheellisesti positiivisia tuloksia. Tämä onkin yksi anomalioiden tunnistamisen suurimmista ongelmista, johon ei pystytä varautumaan ilman käyttäjän syöttämiä muuttujia kausivaihteluista, kampanjoista tai muista tilastoihin vaikuttavista hypoteeseista.
Huomioithan, että mittarit tarvitsevat kohtalaisen suuren otannan toimiakseen kunnolla: Google on itse ilmoittanut, että aikasarjamittarit vaativat kaksi viikkoa aikaa kerätä koulutusdataa koneoppimisen malleille custom insightsin päällekytkemisestä tai muokkaamisesta.
Lisää tietoa GA4 anomalioiden tunnistamisesta löytyy Googlen omasta dokumentaatiosta .
Taso 2: Keskihajonta
Standardipoikkeama tai keskihajonta on tilastollinen mittari, jonka avulla voidaan ilmaista kuinka monen keskihajonnan verran havainto poikkeaa keskiarvosta (mean) valitussa aineistossa. Yksinkertaisin tapa visualisoida standardipoikkeama, on tarkastella sitä normaalijakauman kellokäyrällä (kuva 1).
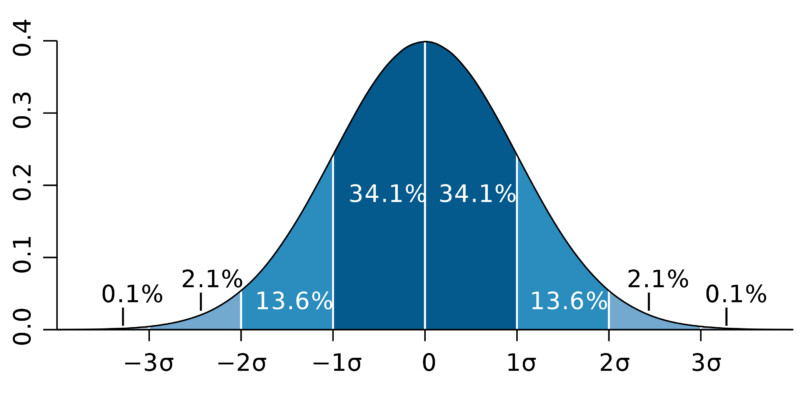
Kuva 1. Standard deviation diagram. M. W. Toews, 2007. CC BY 2.5 https://creativecommons.org/licenses/by/2.5/deed.en
Kellokäyrä kuvastaa kuinka useimmat satunnaiset havainnot ryhmittyvät keskiarvon ympärille noudattaen normaalijakaumaa, jossa puolet havaintopisteistä ryhmittyy keskiarvon alapuolelle (vasemmalle) ja puolet keskiarvon yläpuolelle (oikealle). Huomaathan, että kaikki tilastot eivät noudata normaalijakaumaa. Normaalijakaumaa noudattavissa tilastoissa 68 % havainnoista sijoittautuu yhden (1σ) keskihajonnan sisään, 95 % kahden (2σ) keskihajonnan sisään ja 99.7 % kolmen (3σ) keskihajonnan sisään.
Perustuen aineiston herkkyyteen heilahteluille, määritellään laskennalle kertaluonteinen standardipoikkeama esimerkiksi 3σ. Kertaluonteisen standardipoikkeaman avulla lasketaan aineistolle kynnysarvot: yläraja (upper threshold) ja alaraja (lower threshold).
Mikäli jokin havainto ylittää kynnysarvon, voimme lähteä tarkastelemaan sitä poikkeamana. Laskentatapa on kuitenkin herkkä myös virheille, sillä kaikki tilastot eivät noudata normaalijakaumaa, tai ne ovat herkkiä kausivaihtelulle ja aiheuttavat virheellisiä hälytyksiä.
Taso 3: Koneoppimisen mallit
Koneoppimisen mallien hyödyntäminen anomalioiden tunnistamiseen onnistuu esimerkiksi Google BigQueryn ML.DETECT_ANOMALIES funktiolla ja sen tarjoamilla koneoppimisen malleilla. Tämä ei ole ainoa tapa hyödyntää koneoppimista anomalioiden tunnistamiseen, mutta se on GA4-datan käytettävyyden kannalta yksinkertaisin. Olettaen, että GA4-käyttöliittymässä BigQuery export on kytketty päälle ja historiadataa on saatavilla.
Googlen detect_anomalies funktiossa on kolme mallia joiden perusteella dataa voidaan tarkastella: autoencoder, k-means tai ARIMA_PLUS. Näistä kolmesta mallista kaksi ensimmäistä tarkastelevat havaintoarvoja kokonaisuutena. Viimeisin, ARIMA_PLUS, puolestaan analysoi dataa aikasarjana ja tunnistaa anomaliat aikaleiman luottamusvälien perusteella.
Autoencoder on neuroverkkomalli, joka oppii dataa tiivistämällä sen pieneen edustukseen ja sitten purkamalla sen takaisin alkuperäiseen muotoon. Anomalioita havaitaan vertaamalla alkuperäisen ja tiivistetyn datan eroa. Jos ero ylittää määritetyn kynnyksen, datapiste merkitään anomaliaksi.
K-means on ryhmittelymalli, joka luokittelee datapisteet ryhmiin niiden samankaltaisuuden perusteella. Anomalian tunnistaminen tapahtuu tarkastelemalla, kuinka kaukana datapiste on sen ryhmän keskipisteestä. Jos etäisyys ylittää asetetun kynnyksen, datapiste merkitään anomaliaksi.
ARIMA_PLUS on aikasarjamalli, joka tarkkailee historiallista dataa ja ennustaa tulevaa. Anomalioita tunnistetaan tarkastelemalla, kuinka hyvin todelliset havainnot vastaavat ennusteita. Jos datapiste sijaitsee ennustetun vaihteluvälin ulkopuolella, se merkitään anomaliaksi.
Lisää ML.DETECT_ANOMALIES funktion mallien käyttämisestä löydät Googlen blogista: https://cloud.google.com/blog/products/data-analytics/bigquery-ml-unsupervised-anomaly-detection.
Miten liikkeelle?
Poikkeamien tunnistaminen verkkosivustodatasta edesauttaa ymmärtämään verkkosivuston muuttuvia tilanteita ja nopeuttamaan reagointia poikkeavissa tilanteissa. Suosittelen lähtemään liikkeelle kokeilemalla GA4 custom insights -työkalua, mikäli alusta on jo käytössä. Tällä saat yksinkertaisesti ja helposti syväluotaavan näkemyksen verkkosivustodatasta.
Sivustoilla joilla on jokin vaihtoehtoinen sivustoanalytiikka tai toivotaan enemmän kontrollia poikkeamien tunnistamiseen lähtisin liikkeelle keskihajonnan avulla. Keskihajonnalla poikkeamine tunnistaminen on verrattaen yksinkertaista ja nopea toteuttaa niin laskentatauluissa kuin tietovarastoissa.
Koneoppimisen malleja voin suositella suurille dataseteille, mutta suosittelen mallien perusteellista opiskelua ennen niiden käyttöönottoa. Funktioiden ohjeet ovat varsin suoraviivaisia (Google BigQuery) ja ne antavat käyttäjälle rivikohtaisen boolean arvon poikkeamista. Todellista analyysia varten tuloksia on kuitenkin hyvä ymmärtää syvällisemmin, miksi saimme poikkeaman, onko poikkeama merkittävä, onko tapahtunut laskuvirhe tai virhe aineistossa?