

Suurin osa ihmisistä oppii elämänsä varrella, että vaikka rakastaa jotain todella paljon, se ei välttämättä rakasta sinua takaisin.
Sama pätee myös Googleen. Vaikka kuinka haluaisit kävijöitä Googlen orgaanisesta hausta, et välttämättä saa niitä.
Ehkä Googlebot ei arvosta sisältöäsi. Ehkäpä sivuston tekniikka ei ole kunnossa. Tai ehkä haaskaat hakukonerobottien sivustollesi antaman huomion, crawl budgetin, tarpeettomasti.
Mikä sitten on crawl budget? Google itse määrittelee sen näin (lähde):
We define crawl budget as the number of URLs Googlebot can and wants to crawl.
Kiinnitä huomiota sanoihin ”can” ja ”wants”. Näiden molempien ehtojen täytyy täyttyä, jotta Googlebot haluaa näyttää sivustosi sivuja hakutuloksissaan.
Molempiin asioihin voi vaikuttaa omilla toimenpiteillä, mutta et voi olla varma missä osoitteissa Googlebot vierailee. Vai voitko?
Kyllä voit. Asian paljastaa serverilogianalyysi.
Serverilogit kertovat, missä hakurobotit käyvät
Yksi web-analytiikan ja mittaamisen haasteita on se, että ihmiset saattavat blokata itsensä pois esimerkiksi Google Analyticsistä selaimeen asennettavalla lisäosalla tai ad blockerilla.
Mutta kaikista vierailuista jää aina merkintä serverilogeihin. Tämä sama asia pätee myös hakukonerobotteihin, kuten Googlebottiin.
Siispä ainoa tapa saada varmuus siitä, missä hakukonerobotit käyvät, on kurkata pellin alle serverilogeihin. Ja tutkimalla serverilogeja, voit nähdä selkeästi, mitä sisältöjä Googlebot voi ja haluaa lukea. Näiden löytöjen avulla voit siis optimoida sivustosi crawl budgetia.
Luettuasi seuraavat case-esimerkit, ymmärrät miten arvokasta tietoa serverilogianalyysillä voi saada irti.
Case 1: Suuri mediasivusto
Kyseessä on suuri suomalainen mediasivusto, jossa julkaistun sisällön elinkaari on kohtalaisen lyhyt, sillä sisällöt eivät yleensä ole enää ajankohtaisia muutama kuukausi julkaisun jälkeen. Olen muokannut kansiorakenteiden nimiä, enkä mainitse yrityksen nimeä, mutta muuten data on täysin alkuperäistä.
Sivusto on massiivinen. Tästä hyvänä osoituksena on se, että sillä on Googlen hakutuloksissa yli 500 000 sivua.
Laajuus antaa erinomaiset mahdollisuudet löytyä suurella määrällä hakusanoja hakutuloksista ja luo pohjan oman toimialan dominoimiseen. Samalla laajuus on myös suuri haaste. Miten kokonaisuutta voidaan hallita ja johtaa järjestelmällisesti ja varmistaa, että kaikki liiketoiminnan kannalta tärkeimmät sivut ovat löydettävissä?
Koska sivuston sisältöjen elinkaari on kovin lyhyt, tein alkuun analyysin siitä, miten vanhoissa sisällöissä Googlebot vierailee. Tässä data serverilogianalyysin pohjalta:
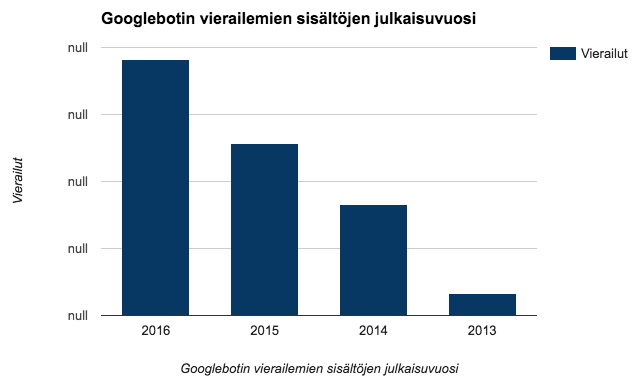
Googlebot on käyttänyt suurimman osan ajasta vuoden 2016 sisällöissä, mikä on hyvä asia. Mutta vanhentuneiden sisältöjen osuus on kuitenkin korkea, sillä noin puolet Googlebotin vierailuista ohjautui reilusti vanhentuneisiin sisältöihin:
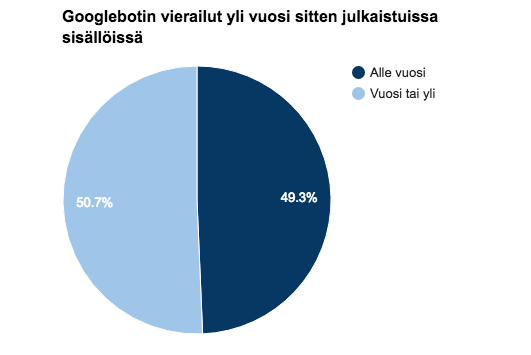
Miksi tällä sitten on väliä?
Koska yli vuosi sitten julkaistut sisällöt eivät ole Googlen käyttäjille relevantteja tuloksia. Kuvittele, että hakisit lippuja ensi kesän Ilosaarirockiin ja sinut ohjattaisiin sivulle, joka listaa vuoden 2014 esiintyjät. Kiva juttu, mutta ei sitä mitä hait.
Kun tähän vielä yhdistää pari muuta asiaa sivustolta, kuten uudelleenohjaukset ja 404-virhesivut, huomataan, että Googlebot viettää kohtalaisen pienen osan huomiostaan halutuilla sivuilla.
Sivuston tekniikassa oli myös erikoinen yksityiskohta. Sivuston sisäistä hakua käyttäessä sivusto teki ensiksi kutsun yhteen osoitteeseen, josta käyttäjä ohjattiin toiseen osoitteeseen. Eli välissä oli yksi ylimääräinen osoite.
Googlebotille tämä tarkoitti sitä, että hekin kävivät alkuun väliaikaisessa osoitteessa, josta sitten etenivät varsinaiseen käyttäjälle näkyvään osoitteeseen.
Tämä ei välttämättä ole ongelma, mutta se on yksi osoitus siitä, että sivuston tekniikalla ja sen logiikalla on merkitystä paitsi käyttäjien myös hakukoneiden kokemukseen sivustosta.
Kaikkiaan sivuston crawl budget jakautui seuraavasti:
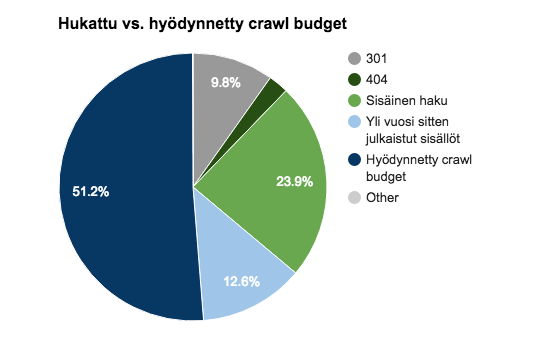
Käytän termiä ”hukattu” kohtalaisen ankarasti, sillä olen kategorisoinut siihen kaikki Googlebotin vierailut, jotka eivät ole toivotuille sivuille.
Case 2: Kansainvälisesti toimiva yritys
Toinen esimerkki on kansainvälisesti toimivalta suomalaiselta yritykseltä. Tämä sivusto on selkeästi suppeampi kuin ensimmäisessä casessa ja on kokoluokaltaan tyypillisempi muutaman sadan sivun laajuinen sivusto.
Olen jälleen kerran muuttanut sivusto-osioiden nimiä, mutta muuten data on täysin oikeaa.
Tällä yrityksellä oli sivustouudistus joitakin kuukausia sitten. Sivustouudistuksen aikana muuttui sekä ulkoasu että sivuston rakenne. Tarkoittaen esimerkiksi kaikkien sivuston URL-osoitteiden muuttumista.
Serverilogianalyysi toi esille muutaman huolestuttavan asian sivuston nykytilasta ja siitä, miten Googlebot sivustolla vieraili:
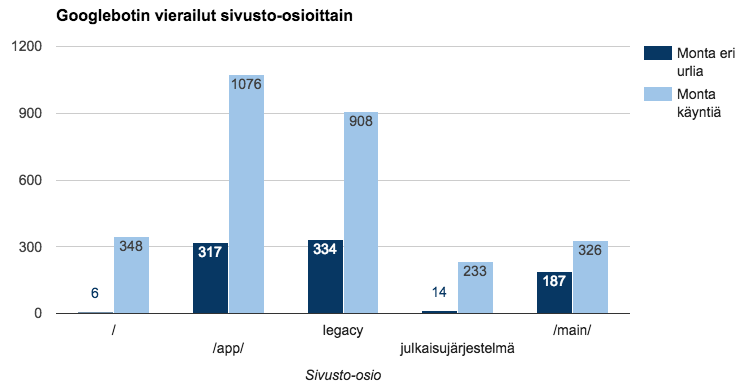
Tässä lyhyesti kuvattuna sivuston eri osiot:
- / = etusivu
- /app/ = sivuston taustajärjestelmiä
- /legacy/ = sivustouudistusta edeltäneitä osoitteita
- julkaisujärjestelmä = esimerkiksi CSS- ja JavaScript-tiedostoja
- /main/ = varsinainen sivusto etusivua lukuunottamatta
Listatuista sivusto-osioista Googlebotin ei tarvitse juurikaan vierailla /app/ -kansiossa eikä etenkään /legacy/ -osiossa, joka koostuu useiden vuosien takaisen sivustouudistuksen osoitteista. Nämä olivat kuitenkin Googlebotin eniten vierailemat osiot!
Huomion arvoista on myös se, että Googlebot on vieraillut useammin etusivulla kuin kaikilla muilla sivuston sivuilla yhteensä.
Seuraava kuvaaja avaa kokonaistilannetta vielä paremmin:
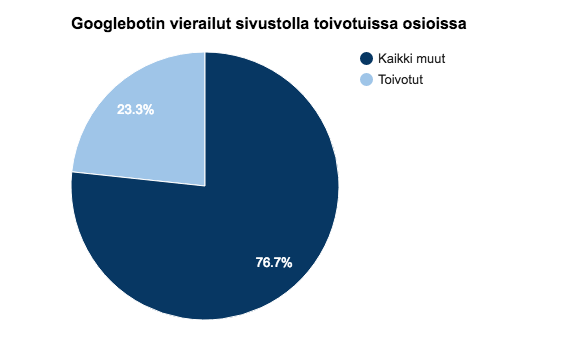
Tässä sivustossa yllätti /legacy/- sekä /app/ -osioiden saama huomio. Legacy-osiosta oli tehty uudelleenohjauksia, mutta niissä oli vielä jotain aukkoja, jotka tilkittiin serverilogianalyysin perusteella. Samoin /app/ -osion roolia pienennettiin tekemällä muutoksia esimerkiksi hakurobottien crawlauksen ohjaamiseen.
Näitä molempia asioita ja etenkin niiden laajuutta olisi ollut mahdoton tietää ilman kurkkaamista pellin alle serverilogeihin.
Muutama sana datasta ja sen analysoinnista
Tässä vaiheessa hakukoneoptimoinnista perillä olevat henkilöt saattavat miettiä, että näkeehän Search Consolesta dataa crawlattavuudesta. Tässä otos case 2:n Search Console -datasta, jossa punaisella on korostettu analyysin aikajakso:
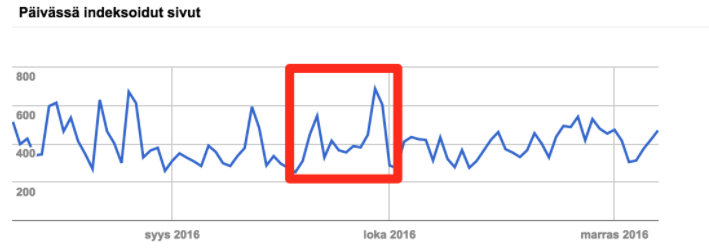
Data näyttää hyvältä siihen asti, kun sitä vertaa oikeisiin serverilogi-osumiin:
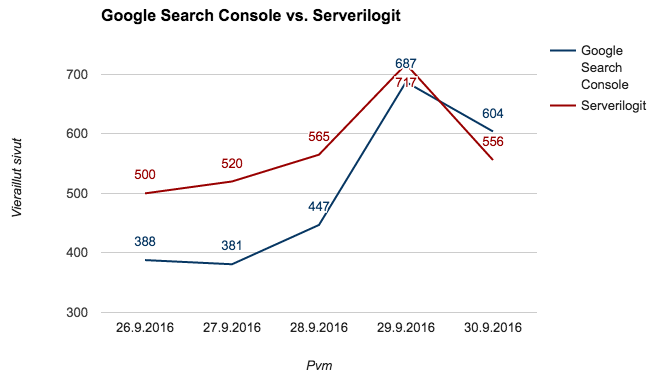
Lukuja vertailemalla näkee, että Search Consolen dataan ei voi luottaa sokeasti, sillä heittoa oikeisiin lukuihin on kohtalaisen paljon. Googlen Search Console ei myöskään kerro, millä sivuilla Googlebot on vieraillut.
Toinen datan laatuun liittyvä asia löytyy varsinaisista serverilogeista. Tässä esimerkki siitä, miltä rivi serverilogia voi näyttää:
[x_code]66.249.64.42 – – [26/Sep/2016:03:59:28 +0300] ”GET /example/ HTTP/1.1” 200 13015 ”-” ”Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”[/x_code]
Yllä olevan rivin alussa oleva IP-osoite (66.249.64.42) kertoo mistä kyseinen kävijä, tai tässä tapauksessa botti on saapunut sivustolle. Rivin lopussa oleva ”Googlebot/2.1; +http://www.google.com/bot.html” taas kertoo kyseessä olleen Googlebot.
Asia selvä? No ei ihan.
Esimerkiksi moni SEO-ammattilaisten käyttämä työkalu voi tunnistautua Googlebotiksi, vaikka kyseessä olisi Joona OIKIOlta. Ja rehellisyyden nimissä, se olen aika usein minä eikä Googlebot 🙂
Tästä syystä serverilogeja analysoidessa täytyy käyttää Reverse IP-lookup -menetelmää, jolla voidaan selvittää, onko käynnit todellakin Googlelta vai joltain taholta, joka esittää olevansa Google. Esimerkiksi mediasivustoa analysoidessani 47 eri IP-osoitetta sanoi olevansa Googlebot, mutta oikeasti pelkästään 14 oikeasti oli.
Oikea data näyttää jotakuinkin tältä:
Työkaluna Excel tai Google Spreadsheets riittää serverilogien analysointiin suurimmassa osassa tapauksista ellei aikajänne ole todella pitkä ja sivusto äärimmäisen vierailtu. Jos näin on, voidaan tarvita järeämpää softaa, kuten Splunk.
Esimerkiksi mediasivustoa analysoidessa serverilogeista jäi jäljelle 200000-300000 riviä Googlebotin käyntien erottelun jälkeen. Samalla tuli todettua, että Google Spreadsheetsin kahden miljoonan solun raja voi tulla yllättävän nopeasti vastaan 🙂
Mitä tehdä kun sisältösi ei saa riittävästi rakkautta hakuroboteilta?
Ihan ensiksi kannattaa varmistaa, että salliiko sivustosi hakurobottien käynnit tai onko niiden käynnit rajoitettu pois jostain tärkeistä osioista.
Jos robotit pääsevät vierailemaan kaikilla tärkeillä sivuilla, kysy itseltäsi seuraavat kysymykset:
- Onko kyseessä todella laaja sivusto, esimerkiksi verkkokauppa?
- Onko sivustolle tehty viime aikoina sivustouudistus?
Jos et vastaa kumpaankaan kysymykseen ”kyllä”, serverilogianalyysin tekeminen on ehkä turhan kova toimenpide. Ratkaisu löytyy todennäköisesti muualta sivuston tekniikasta.
Yleensä hakukoneilta saa lisää rakkautta esimerkiksi varmistamalla seuraavat asiat:
- Onhan sivustokarttasi ajan tasalla ja niiden sijainti Googlebotin ja muiden robottien löydettävissä?
- Palauttaahan kaikki sivustokarttatiedostoissa olevat URL-osoitteet 200-tilakoodin, eikä joukosta löydy esimerkiksi 404-sivuille ohjaavia linkkejä?
- Antaahan sisäiset linkit robottien seurata niiden osoittamiin URL-osoitteisiin? Tämä on tärkeää etenkin navigaation suhteen.
- Onhan sivuston hierarkia järkevästi rakennettu ja kaikkiin tärkeisiin osioihin osoittaa sisäisiä linkkejä?
- Onhan sivuston sisällöt optimoitu hyvin? Ota mallia vaikka Zalandolta tai lue vinkit SEO-sisällön kirjoittamiseen.
- Eihän hakurobottien liikkeitä rajoiteta väärin robots.txt:n tai meta=”robots”-tagien avulla?
- Toisaalta, eihän sivusto vuoda hakutuloksiin sinne kuulumattomia sivuja, kuten sisäisen haun hakutulos-sivuja tai suppeita käyttäjille mitäänsanomattomia sivuja?
Yllä oleviin kysymyksiin vastaamalla pääsee erittäin hyvin alkuun hakukonenäkyvyyden kehittämisessä. Jos et ole varma tilanteesta, teetätä sivustostasi tekninen SEO auditointi.
Joka tapauksessa kannattaa muistaa, että hakukoneoptimointi on pitkäjänteistä ja järjestelmällistä työtä eikä välittömiä muutoksia kannata odottaa. Googlebot on aivan kuten elämänkumppani: se tykkää siitä, että sitä kohdellaan hyvin jatkuvasti, ei vain silloin tällöin.