



Viime aikoina Pythonin käyttö ja hype on kasvanut SEO-piireissä. Python on koodikielenä kohtalaisen yksinkertainen, laskutehoiltaan voimakas sekä taipuu eri käyttötarkotuksiin. Tämä on puolestaan ajanut hyvin sen asiaa eteenpäin. Pythonilla voi esimerkiksi:
- Kerätä tietoja verkkosivuilta tai tietokannoista
- Analysoida ja visualisoida dataa
- Luoda koneoppimismalleja
- Luoda erilaisia SEO-scriptejä
Tässä artikkelissa kuitenkin keskitymme nimenomaan tietojen koneelliseen keräämiseen (eli scraping) verkkosivuilta. Tietojen kerääminen verkkosivuilta voi tulla hyödylliseksi esimerkiksi, jos haluat vertailla oman verkkokaupan tuotteiden hintoja kilpailijan hintoihin tai tutkia varastosaatavuuksia. Tässä tilanteessa voit luoda skriptin, joka käy hakemassa päivittäin kilpailijan verkkokaupan tuotteet ja hinnat sekä lisää nämä tiedot tietokantaan. Ongelma ratkaistu.
Alla olevaan artikkeliin vaaditaan hieman perustaitoja syvällisempää tietoa tietokoneen käytöstä sekä HTML:stä. Artikkelissa prosessista on käytetty termiä “screipata”.
Alla oleva artikkeli on irrotettu OIKIOn sisäisestä knowledgebasesta, jonne kootaan ja luodaan eri osaamisalueisiin liittyviä, oikiolaisten tekemiä ohjeita ja oppaita. Knowledgebasen ajatuksena on jakaa yksittäisten OIKIOn asiantuntijoiden ammattitaitoja muiden oikiolaisten kesken. Knowledgebasesta löytyy myös runsaasti erilaisia templaatteja ja automaatioita, joiden kautta voidaan säästää aikaa ja keskittyä olennaiseen, eli arvon tuottamiseen asiakkaalle turhan excel-jumpan sijasta!
Screippaaminen Pythonilla ja BeautifulSoup-kirjastolla
Alla lyhyt ja ytimekäs opas screippaamiseen Pythonilla. Tarvitset seuraavat asiat:
- tietokone
- internet
- Anaconda
- Jupyter notebooks (löytyy anacondasta)
Aloitetaan
Tietokoneen terminaaliin pitää kirjoittaa seuraavat asiat, jotta tarpeelliset kirjastot asentuvat:
pip install beautifulsoup4
pip install requests
pip install fake-useragent
Seuraavaksi avataan Anacondasta Jupiter Notebook ja uusi Python 3 -tiedosto.
Uuden tiedoston ensimmäiseen laatikkoon tuodaan nämä kirjastot:
from bs4 import BeautifulSoup
import requests
from fake_useragent import UserAgent

Tämän jälkeen pitää valita, mitä URLia lähdetään screippailemaan.
Tässä esimerkissä käytetään Tutustu asiantuntijatiimiimme -sivun URLia ja koitetaan screipata kaikkien oikiolaisten nimet ja tittelit.
Avataan yhteys ja haetaan lähdekoodi
Käytetään screippailussa feikki-useragentteja, jotta sivustot eivät tunnista meitä botiksi ja estä pääsyä sivulle. Valmistellaan se ensin:
ua = UserAgent()
header = {'user-agent':ua.chrome}
Sitten luodaan muuttuja URLille, jota halutaan screipata:
url = 'https://oikio.fi/asiantuntijatiimi/'
Avataan yhteys URLiin (tässä käytetään sitä feikki-useragenttia):
page = requests.get(url,headers=header)
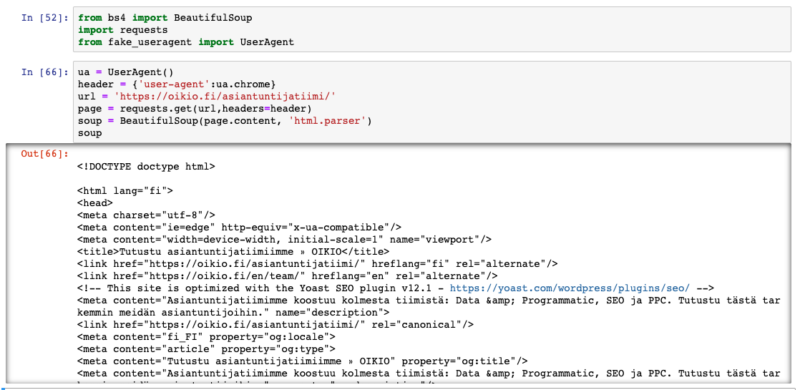
Käytetään BeautifulSouppia (BS), jolla voidaan jäsennellä html:ää paremmin ja tallennetaan se ’soup’-muuttujaan:
soup = BeautifulSoup(page.content, 'html.parser')
Nyt siis voimme viitata sivun lähdekoodiin pelkästään ’soup’illa.
Etsitään halutut elementit lähdekoodista
BeautifulSoupin avulla voidaan siis etsiä mitä tahansa elementtejä sivuston html:stä.
Yksinkertaisimmillaan se toimii niin, että laitetaan pisteen perään haluttu elementti, niin BS palauttaa ensimmäisen html:stä löydetyn elementin. Tämä toimii hyvin esim titlelle.
Jos halutaan löytää sivun title, se saadaan haettua kirjoittamalla Anacondaan ja ajamalla rivin:
soup.title
Mikä palauttaa:
<title>Tutustu asiantuntijatiimiimme » OIKIO</title>
Jos halutaan ainostaan elementin teksti ilman <title>-tageja, saadaan se laittamalla .text perään:
soup.title.text
Find_all -funktio
Yksi käytetyimmistä ja hyödyllisimmistä funktioista BeautifulSoupin kirjastosta, jolla voi etsiä mitä tahansa sivulta, on find_all -funktio.
Kyseinen funktio etsii annettujen parametrien avulla kaikki kriteerit täyttävät elementit ja palauttaa ne listana.
Esimerkiksi jos halutaan kaikki lista-itemit sivulta, saadaan ne näin:
all_li = soup.find_all('li')
Jos halutaan tarkentaa hakua, esimerkiksi screippaamalla vain tietyn classin tai id:n omaavat lista-itemit, voidaan se tehdä näin:
all_li = soup.find_all('li', class_ = 'haluttu-class')
all_li = soup.find_all('li', id_ = 'haluttu-id')
Aloitetaan oikiolaisten screippaus
Kun tutkitaan Chromen developer-toolseista mitä sivu on syönyt huomataan, että kaikki henkilökortit ovat divin sisällä, jonka class on single-person (näkyy heikosti kuvakaappauksessa):
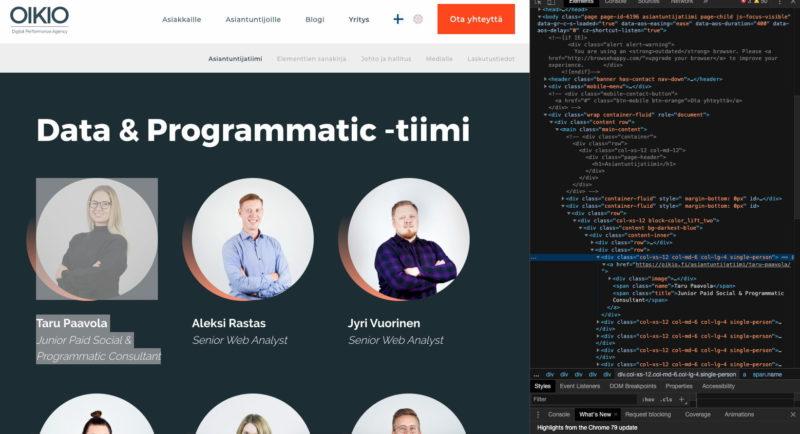
Käydään hakemassa kaikki nämä divit muuttujaan henkilo_div:
henkilo_div = soup.find_all('div', class_ = 'single-person')
henkilo_div:ssä on nyt lista kaikista henkilökorteista. Jos katsotaan ensimmäistä:
henkilo_div[0] //ensimmäinen lista-itemi
Saadaan elementin HTML-koodi:
<div class="col-xs-12 col-md-6 col-lg-4 single-person">
<a href="https://oikio.fi/asiantuntijatiimi/taru-paavola/">
<div class="image">
<img src="/wp-content/uploads/2019/11/taru_pieni.jpg"/>
</div>
<span class="name">Taru Paavola</span>
<span class="title">Paid Social & Programmatic Consultant</span>
</a>
</div>
Huomataan, että ensimmäisessä spanissa on nimi, toisessa titteli. Nämä saadaan esimerkiksi käyttämällä uusiksi find_all -funktiota, mutta tällä kertaa etsitään spaneja henkilo_div:stä.
Sillä divejä(työntekijöitä) on useita, joudutaan looppaamaan kaikkien niiden yli for-loopin avulla:
Lähdetään siis käymään henkilo_div -listaa läpi, haetaan spanit, määritellään nimi ja titteli sekä printataan ulos ”nimi: titteli”
for henkilo in henkilo_div:
spanit = henkilo.find_all('span') //etsitään spanit
nimi = spanit[0].text //ensimmäinen spani oli nimi, otetaan sen teksti
titteli = spanit[1].text //toka spani oli titteli
print(nimi, ": ", titteli) //printataan
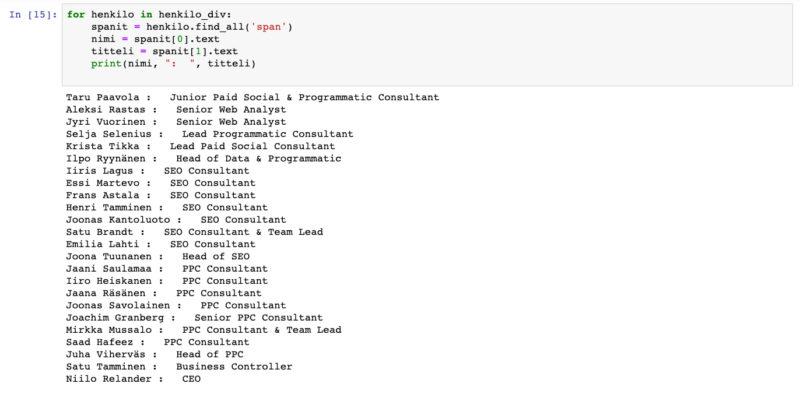
Ja lopputulos pitäisi olla jotain tämän näköistä:
Jes! Saatiin haluttu lopputulos! Koko lähdekoodi löytyy OIKIOn julkisesta Github-repositorystä.
Hyvää screippailua 🙂


